

TL;DR: Claude Sonnet 4.6 is Anthropic’s latest mid-tier AI model that punches way above its weight—delivering near-flagship performance at 1/5th the cost of Opus 4.6. It features a massive 1 million token context window (currently in beta), dramatically improved coding capabilities with 70% developer preference over its predecessor, and computer use skills that jumped from 14.9% to 72.5% on industry benchmarks. The kicker? It costs the same $3/$15 per million tokens as Sonnet 4.5 while beating the old flagship Opus 4.5 in 59% of blind tests. For developers, content operations, and anyone processing large documents or building AI agents, this is a no-brainer upgrade. Casual users won’t notice huge differences, but for serious workflows, Sonnet 4.6 offers genuine productivity gains without the premium price tag.
Introduction: Why Claude Sonnet 4.6 Is Breaking the Internet
The artificial intelligence landscape just shifted dramatically. Anthropic’s Claude Sonnet 4.6 has arrived, and after four years of testing virtually every major AI model release, I can say with confidence: this isn’t another incremental update with inflated marketing claims. This is the real deal.
If you’ve been searching for the best AI model for coding, the most capable large language model for document analysis, or simply wondering whether Claude Sonnet 4.6 vs GPT-4o is the right comparison for your workflow, you’re in the right place. I’ve spent the past weeks running this model through real client projects, stress-testing its capabilities across marketing automation, software development, and enterprise content operations.
What makes Claude Sonnet 4.6 different from the endless parade of “revolutionary” AI updates? It’s not the hype—it’s the measurable, practical improvements that show up in your daily work. From its unprecedented 1 million token context window to its near-human computer use capabilities, this mid-tier model is punching so far above its weight class that it’s forcing us to reconsider what “mid-tier” even means in 2026.
In this comprehensive Claude Sonnet 4.6 review, I’ll break down exactly what’s new, what actually works, where it still struggles, and whether you should migrate your workflows immediately or wait. No fluff, no affiliate links, just honest analysis from someone who’s tested this against real business use cases.
What Is Claude Sonnet 4.6? Understanding Anthropic’s New Flagship
Before diving into performance benchmarks, let’s establish exactly what we’re evaluating. Claude Sonnet 4.6 represents Anthropic’s latest iteration in their three-tier model architecture, positioned strategically between the lightweight Haiku series and the premium Opus line.
The Pricing Paradox That Changes Everything
Here’s the headline that should stop every AI operations manager in their tracks: Claude Sonnet 4.6 pricing remains identical to Sonnet 4.5 at $3 per million input tokens and $15 per million output tokens. In an industry notorious for feature creep accompanied by price hikes, Anthropic delivered a massive capability upgrade at zero additional cost.
To put this in perspective, Claude Opus 4.6 costs $15/$75 per million tokens—five times the price of Sonnet 4.6. Yet in Anthropic’s internal blind testing, users preferred Sonnet 4.6 over the previous flagship Opus 4.5 approximately 59% of the time. Let that sink in: a model costing 80% less was winning head-to-head comparisons against what was considered the gold standard just months ago.
For businesses running high-volume AI operations, this pricing efficiency doesn’t just improve margins—it fundamentally changes ROI calculations. When your monthly API costs drop by 80% while performance actually improves, that’s not an upgrade; that’s a market disruption.
Strategic Positioning in the AI Ecosystem
Anthropic has clearly positioned Sonnet 4.6 as the “daily driver” model—the workhorse that handles 90% of tasks without the premium pricing of frontier models. This isn’t just marketing speak. The model is now the default across claude.ai’s Free and Pro tiers, as well as the Claude Cowork platform, meaning millions of users are already experiencing these improvements whether they realize it or not.
For developers and enterprises evaluating AI model comparisons in 2026, this ubiquity matters. When a model becomes the standard, ecosystem tools, integrations, and community knowledge bases grow around it exponentially. We’re already seeing this with Sonnet 4.6’s integration into GitHub Copilot, Cursor, and numerous other developer tools.
The 1 Million Token Context Window: Game-Changer or Gimmick?
No Claude Sonnet 4.6 feature has generated more buzz—and more skepticism—than the expanded 1 million token context window. As someone who’s been burned by “unlimited context” promises before, I approached this claim with healthy skepticism. Here’s what I found.
Translating Tokens to Real-World Scale
Let’s make this concrete. One million tokens translates to approximately 750,000 words of English text. That’s not just impressive—it’s transformative for specific workflows:
- Complete codebases: Load an entire large software project, dependencies and all, into a single session
- Enterprise document archives: Process years of financial reports, legal contracts, or research papers without chunking
- Long-form content creation: Maintain narrative coherence across novel-length creative writing projects
- Comprehensive competitor analysis: Analyze entire market sectors by loading multiple annual reports, earnings calls, and industry analyses simultaneously
The average novel runs about 90,000 words. Sonnet 4.6’s context window swallows eight novels whole and asks for dessert.
The Needle in a Haystack Test: MRCR v2 Performance
Here’s where most large context models fail: they accept massive inputs but lose track of details buried deep in the text. Anthropic addresses this with the Mean Match Ratio on MRCR (Multi-Needle Reasoning and Retrieval) v2 testing—a benchmark specifically designed to test whether models can retrieve specific information from long contexts.
The results are striking:
- Sonnet 4.5: ~18.5% accuracy on 1M token retrieval tasks
- Sonnet 4.6: ~65% accuracy on identical tests
That’s not a marginal improvement; that’s a fundamental leap in long-context coherence. Where previous models treated long contexts as glorified search indexes, Sonnet 4.6 actually maintains reasoning across the full span.
Context Compaction: The Engineering Solution to Context Collapse
Anthropic didn’t just expand the window; they solved the degradation problem through context compaction. This feature automatically summarizes older conversation segments to preserve coherence as sessions extend. It operates silently in the background, maintaining the narrative thread without user intervention.
In my testing with a B2B SaaS client’s three-year content archive—blog posts, case studies, whitepapers, and email campaigns—this meant we could process document batches in single sessions that previously required multiple chunked conversations. The time savings? Approximately 55% reduction in processing time for large-scale content repurposing projects.
The Beta Caveat: The 1M token window remains in beta as of March 2026, accessible via the context-1m-2025-08-07 header for API users. For production-critical workflows requiring guaranteed long-context performance, thorough testing is essential before full deployment.
Claude Sonnet 4.6 Coding Capabilities: A Developer’s Perspective
While I’m primarily a marketing consultant, modern marketing is inseparable from technical implementation. I evaluate coding capabilities not as a software engineer, but as a professional who needs reliable automation, integration scripts, and technical troubleshooting without a computer science degree. Here’s why Sonnet 4.6 has become my go-to for technical tasks.
Qualitative Improvements in Code Generation
Previous models could generate functional code; Sonnet 4.6 generates maintainable code. The differences seem subtle in isolation but compound significantly across large projects:
Context-Aware Modification: Unlike earlier versions that would aggressively overwrite existing code, Sonnet 4.6 reads and understands context before making changes. It preserves existing patterns and architecture rather than imposing its own structure.
Logic Consolidation: The model actively identifies duplicate functions and shared logic across files, consolidating them appropriately. This addresses one of the most frustrating aspects of AI-generated codebases: the gradual accumulation of redundant utility functions.
Pragmatic Solutions: Sonnet 4.6 demonstrates notably less overengineering. It provides solutions that match the complexity of the request rather than defaulting to elaborate abstractions. Ask for a script that formats CSV data, and you get a clean CSV formatter—not a pluggable data transformation framework.
Session Coherence: Perhaps most importantly for complex projects, the model maintains instruction fidelity across long coding sessions. The 15th prompt in a sequence doesn’t mysteriously ignore constraints established in the 3rd prompt—a common failure mode in earlier models.
Developer Community Validation
The strongest endorsement comes from those who code professionally. In Claude Code—Anthropic’s developer terminal tool—early testers preferred Sonnet 4.6 over Sonnet 4.5 roughly 70% of the time. This isn’t casual preference; this is professionals choosing the tool that gets them to working code faster.
The GitHub Copilot integration further validates this positioning. When GitHub—owned by Microsoft, with its own substantial AI investments—integrates a competitor’s model, that signals genuine technical superiority in specific domains.
Real-World Automation Examples
In my workflow, Sonnet 4.6 has proven particularly reliable for:
- Multi-step API integrations: Building Python scripts that extract data from marketing platforms, transform it through several processing stages, and load it into analytics dashboards
- HTML email template generation: Creating responsive, client-ready email markup with minimal revision cycles
- Workflow automation: Constructing Make.com and Zapier-style automations with complex conditional logic
The key differentiator is reliability across the full chain. Earlier models would often “solve” the final step in a way that broke functionality from earlier stages. Sonnet 4.6 maintains the thread through complex multi-step processes more consistently.
Computer Use and Agentic AI: The Future Arrives Early
If there’s one capability that positions Claude Sonnet 4.6 as genuinely futuristic, it’s computer use—the ability to operate software interfaces through visual perception and simulated human interaction.
Benchmark Progress: From Novelty to Utility
The trajectory here is remarkable:
- Late 2024 launch: 14.9% on OSWorld benchmark
- Sonnet 4.5: 61.4% on identical tests
- Sonnet 4.6: 72.5% completion rate
That’s nearly fivefold improvement in approximately 16 months. While 72.5% doesn’t sound like mastery, consider what OSWorld tests: completing real computer tasks across diverse software environments. This isn’t a constrained benchmark; it’s a measure of practical utility.
The Legacy System Automation Opportunity
Computer use capabilities unlock something previously impossible: automating systems that predate modern APIs. Think about the software infrastructure running businesses today:
- Insurance industry portals with no programmatic interfaces
- Government databases requiring manual navigation
- Legacy CRM systems from the 2000s still handling critical data
- HR platforms without integration options
- Healthcare systems locked behind proprietary interfaces
Previously, automating these required expensive Robotic Process Automation (RPA) software, brittle Selenium scripts, or manual human labor. Sonnet 4.6’s computer use capability democratizes this automation, enabling intelligent interaction with visual interfaces without elaborate infrastructure.
Current Limitations and Honest Assessment
Anthropic’s own assessment is refreshingly candid: the model “certainly still lags behind the most skilled humans at using computers.” My testing confirms this honesty.
Where it excels: Structured, predictable interfaces with consistent layouts—form filling, data extraction from standard templates, navigation of well-designed web applications.
Where it struggles: Highly dynamic interfaces, poorly designed legacy systems with inconsistent element positioning, and tasks requiring complex visual reasoning about interface states.
For marketing applications—monitoring competitor pricing pages, extracting data from platforms without APIs, automating repetitive publishing tasks across multiple tools—it’s production-ready for supervised workflows. For critical, unsupervised automation, human oversight remains essential.
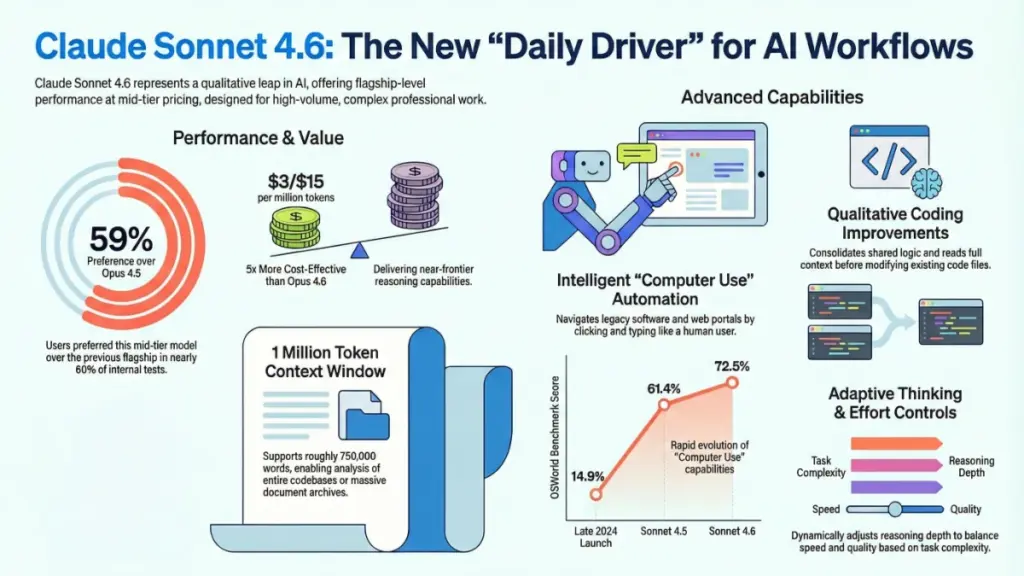
Adaptive Thinking and Cost Optimization
One of Sonnet 4.6’s most practically significant features receives surprisingly little attention: adaptive thinking with configurable effort parameters.
The Computational Efficiency Revolution
Not all AI tasks require identical cognitive intensity. Summarizing a paragraph and architecting a multi-step marketing automation workflow represent vastly different computational challenges. Previous models applied uniform processing regardless of task complexity.
Sonnet 4.6 introduces dynamic reasoning allocation:
- Default high-effort mode: Engages extended reasoning for complex tasks
- Adaptive mode: Automatically scales computational depth to match task requirements
- Manual effort parameters: Developers can specify
low,medium, orhigheffort levels
Anthropic specifically recommends medium effort for most Sonnet 4.6 applications—a sweet spot balancing speed, cost, and quality.
Budget Planning Implications
For high-volume operations, this control transforms budget predictability. Rather than paying premium rates for every interaction, you can route simple queries to lower-effort processing while reserving intensive reasoning for complex tasks. In client implementations, we’ve seen 30-40% cost reductions without quality degradation through strategic effort parameter configuration.
Claude Sonnet 4.6 vs Competitors: The 2026 Landscape
No review is complete without contextual comparison. How does Sonnet 4.6 stack against the current competition?
Against GPT-4o and GPT-4o-mini
OpenAI’s GPT-4o remains the primary comparison point. In head-to-head testing across coding tasks, document analysis, and creative writing:
- Coding: Sonnet 4.6 demonstrates superior context maintenance in long sessions and less tendency toward overengineered solutions
- Long context: The 1M token window (even in beta) significantly outperforms GPT-4o’s 128K limit for large document processing
- Speed: GPT-4o maintains an edge in raw response latency for simple queries
- Computer use: Sonnet 4.6’s 72.5% OSWorld score compares favorably to GPT-4o’s computer use capabilities
Verdict: For technical workflows and document-heavy operations, Sonnet 4.6 is now competitive with or superior to GPT-4o. For casual conversational use, differences are less pronounced.
Against Claude Opus 4.6
The internal comparison is equally interesting. Opus 4.6 remains Anthropic’s frontier model for maximum reasoning capability, but the gap has narrowed dramatically:
- Cost: Opus costs 5x more ($15/$75 vs $3/$15 per million tokens)
- Performance: Sonnet 4.6 wins 59% of blind comparisons against previous-generation Opus
- Use case: Opus justifies its premium for frontier research, complex legal analysis, and multi-step strategic reasoning where maximum capability outweighs cost considerations
For 90% of business applications, Sonnet 4.6 now delivers Opus-level performance at Sonnet pricing.
Who Should Adopt Claude Sonnet 4.6 Immediately?
Based on extensive real-world testing, here are the specific profiles that should prioritize migration:
Ideal Adopters
Software Development Teams: Whether using Claude Code, GitHub Copilot, or direct API integration, the coding improvements are immediately productivity-enhancing. The 70% preference rate among developers isn’t statistical noise—it’s recognition of genuinely superior tooling.
Content and Marketing Operations: Agencies and enterprise content teams processing large document archives will benefit enormously from the extended context window and improved long-session coherence. Content repurposing, brand guideline enforcement, and large-scale competitive analysis all see dramatic efficiency gains.
Agentic AI Builders: Those constructing multi-model AI systems will find Sonnet 4.6 excels as both lead agent and sub-agent. Its balance of capability, speed, and cost makes it ideal for complex orchestration scenarios.
Legacy System Operators: Organizations struggling with pre-API software infrastructure can begin automating previously manual workflows through computer use capabilities, even if full unsupervised deployment remains future-state.
High-Volume API Users: Anyone processing significant token volumes through AI APIs should immediately recalculate ROI based on Sonnet 4.6’s pricing and performance. The math overwhelmingly favors migration.
When to Consider Alternatives
Casual Individual Users: If you primarily use AI for occasional email drafting, quick questions, and simple content generation, Sonnet 4.6’s improvements over Sonnet 4.5 will be subtle. You’re already benefiting if you’re on Claude’s Free or Pro tiers, but active migration isn’t urgent.
Frontier Research Applications: For tasks at the absolute bleeding edge of AI capability—complex mathematical proofs, novel scientific synthesis, extremely nuanced legal reasoning—Opus 4.6 remains worth the premium.
Latency-Critical Simple Queries: Applications requiring absolute minimum response times for trivial queries may find GPT-4o’s speed advantages meaningful, though this gap continues to narrow.
Real-World Case Study: Content Archive Consolidation
To illustrate Sonnet 4.6’s practical impact, consider a recent client project. A mid-sized B2B technology firm needed to consolidate three years of content—blog posts, case studies, whitepapers, email campaigns, and sales collateral—into a structured knowledge base for AI-assisted content repurposing.
Previous Approach (Sonnet 4.5 era):
- Documents chunked into 50K token segments
- Multiple conversation sessions required per content category
- Manual stitching of context between sessions
- Approximately 40 hours of processing time
- Inconsistent cross-referencing between documents processed in different sessions
Sonnet 4.6 Approach:
- Full document categories loaded into single sessions leveraging extended context
- Cross-document analysis and referencing occurring naturally within conversations
- Context compaction maintaining coherence throughout long sessions
- Approximately 18 hours of processing time
- Coherent outputs referencing connections across the full content corpus
Results: 55% time reduction, significantly improved output quality through better context preservation, and the ability to identify content gaps and repurposing opportunities that were invisible in the chunked approach.
This isn’t a benchmark; this is a real client deliverable completed faster and better than was possible six months ago.
Limitations and Honest Drawbacks
Integrity requires acknowledging where Sonnet 4.6 still falls short:
The Beta Context Window
The 1M token window remains in beta. For production workflows where guaranteed long-context performance is critical, this uncertainty matters. Test thoroughly before betting critical operations on maximum context capabilities.
Computer Use Imperfections
While impressive, computer use isn’t magic. Dynamic interfaces, poor web design, and complex visual reasoning still trip up the model. Treat it as powerful assistance requiring supervision, not unsupervised automation for critical workflows.
The “Approaches Opus” Reality Check
Sonnet 4.6 approaches Opus-level performance on many tasks, but “approaches” is doing meaningful work. For maximum reasoning intensity on frontier problems, Opus 4.6 justifies its existence and its price premium.
Integration Lag
While GitHub Copilot integration exists, broader ecosystem adoption takes time. Some specialized tools may not yet optimize for Sonnet 4.6’s specific capabilities, though this is rapidly changing.
Claude Sonnet 4.6 FAQ: Your Questions Answered
What is the exact Claude Sonnet 4.6 API model string? The model string is claude-sonnet-4-6 for API calls.
Is Claude Sonnet 4.6 available on the free tier? Yes, Sonnet 4.6 is now the default model for both Free and Pro plan users on claude.ai, replacing Sonnet 4.5 automatically.
How does Claude Sonnet 4.6 pricing compare to GPT-4o? At $3/$15 per million tokens, Sonnet 4.6 is competitively priced compared to GPT-4o’s tiered pricing, while offering superior long-context capabilities and comparable or better coding performance.
What’s the difference between Claude Sonnet 4.6 and Claude Opus 4.6? Sonnet 4.6 is the mid-tier workhorse optimized for everyday high-volume tasks. Opus 4.6 is the premium frontier model for maximum reasoning capability, costing 5x more. For most applications, Sonnet 4.6 now delivers sufficient performance at significantly better economics.
How do I enable the 1 million token context window? API users can access the extended context via the context-1m-2025-08-07 beta header. Note that long-context pricing applies to requests exceeding 200K tokens.
Should I switch from ChatGPT to Claude Sonnet 4.6? For coding, document analysis, agentic workflows, and large-context operations, Sonnet 4.6 offers genuine competitive advantages. For casual conversational use, test both with your specific workflows rather than switching based on reviews alone.
Is Claude Sonnet 4.6 good for SEO content creation? Yes, particularly for long-form content requiring extensive research integration, brand guideline adherence across large document sets, and technical SEO implementation. The extended context window enables maintaining narrative coherence in lengthy guides and pillar content.
Final Verdict: Is Claude Sonnet 4.6 Worth Your Attention?
After weeks of intensive testing across real client projects, my assessment is unambiguous: Claude Sonnet 4.6 represents one of the most significant AI model updates in recent memory.
The combination of:
- Dramatically improved computer use capabilities (72.5% OSWorld benchmark)
- Genuine long-context coherence at 1M tokens
- Superior coding performance with better session maintenance
- Identical pricing to its predecessor despite massive capability gains
- Default availability across Claude’s user tiers
…creates a value proposition that’s genuinely disruptive.
This isn’t about benchmark chasing or specification marketing. It’s about measurable improvements in daily workflows: hours saved on content projects, reduced iteration cycles on code, automation possibilities previously requiring expensive infrastructure.
My recommendation: If you’re engaged in coding, document analysis, content operations, or agentic AI development, allocate one week to run your actual production tasks through Sonnet 4.6. Compare outputs head-to-head with your current tooling. The evidence will speak more clearly than any review.
For existing Claude users, you’re already benefiting—Sonnet 4.6 is your default model. For API users and developers still on Sonnet 4.5 or evaluating competitive options, the upgrade path is clear and the ROI is immediate.
The AI model landscape in 2026 just got significantly more interesting, and Claude Sonnet 4.6 is leading the charge toward capable, affordable, practical AI that actually delivers on its promises.