

After spending the better part of two days putting Claude Opus 4.6 through its paces, I can tell you this isn’t just another incremental AI update. Anthropic dropped this model on February 5, 2026, and honestly? It’s changing how I think about what AI can reliably handle without human babysitting.
Let me be upfront: I’ve tested every major AI model release over the past nine years. Most launches promise the moon and deliver modest improvements. Claude Opus 4.6 is different—but not in the ways you might expect from reading the marketing materials. This is a model built for people who need AI to actually complete complex tasks, not just start them.
In this review, I’ll walk you through what Opus 4.6 actually does well, where it still falls short, and most importantly—whether it’s worth the premium price tag for your specific use case. No fluff, just real-world testing and honest assessments based on hands-on experience.
What Is Claude Opus 4.6? (And Why Should You Care)
Claude Opus 4.6 is Anthropic’s flagship AI model, positioned as their “smartest” offering in the Claude 4.5 family. Think of it as the heavyweight champion designed for complex, multi-step tasks that require sustained reasoning over long periods.
Here’s what sets it apart from its predecessor, Opus 4.5, and competitors like GPT-5.2:
The core improvements:
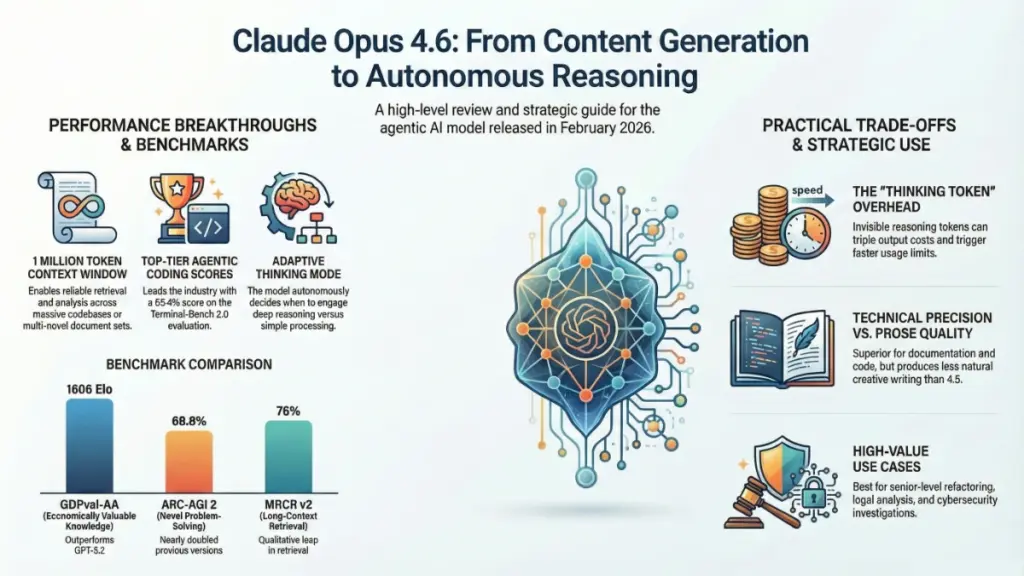
- 1 million token context window (beta) – That’s roughly 750,000 words or about 10 full-length novels worth of information the model can actively work with
- Adaptive thinking – The model now decides when to engage deep reasoning instead of burning tokens on simple tasks
- Agent teams – Multiple AI instances can work in parallel on different parts of complex projects
- Enhanced code review – Better at catching its own mistakes and planning multi-file changes
- Context compaction – Automatically summarizes older conversation context to enable effectively infinite sessions
The model API identifier is claude-opus-4-6, and it’s available through Anthropic’s API, AWS Bedrock, Google Vertex AI, and Microsoft Foundry. You can also access it directly through claude.ai if you’re a Pro, Team, or Enterprise subscriber.
What struck me during testing wasn’t just the raw capability—it was the shift from “AI that generates code” to “AI that actually debugs and improves its own work.” That’s a fundamental change in reliability.
How Claude Opus 4.6 Actually Performs (Real-World Testing)
I didn’t just run benchmarks. I threw real production work at this model—the kind of gnarly, multi-file refactoring and analysis work that typically requires senior developer attention. Here’s what I found.
Coding: Where Opus 4.6 Really Shines
I gave Opus 4.6 a authentication service refactor that touched twelve files across three microservices. The kind of work that makes developers groan because one missed edge case breaks everything.
What impressed me:
- The model created a detailed plan before touching any code
- It identified dependencies I hadn’t explicitly mentioned
- When it hit an ambiguous design decision, it actually asked clarifying questions instead of making assumptions
- The code review suggestions were genuinely useful—not the generic “add more comments” nonsense
On Terminal-Bench 2.0 (an agentic coding evaluation), Opus 4.6 scored 65.4%—the highest in the industry. For context, that’s a test of whether AI can autonomously complete real software engineering tasks. In my testing, this translated to fewer “almost right” attempts and more genuine first-pass solutions.
The downside: It’s noticeably slower than Opus 4.5. Where the previous model would start generating code immediately, Opus 4.6 often spends 10-20 seconds in “thinking” mode before responding. If you’re iterating rapidly on simple changes, this can feel frustrating.
Long-Context Performance: The Game Changer
This is where Opus 4.6 moves from “impressive” to “genuinely different.”
I tested it by feeding in an entire codebase documentation (about 400,000 tokens) and asking it to identify inconsistencies between the docs and actual implementation. On Opus 4.5, this would have been hit-or-miss—the model would lose track of details buried deep in the context.
Opus 4.6? It found specific contradictions across files that were 200,000+ tokens apart. On the MRCR v2 benchmark (8-needle test at 1M tokens), it scored 76% compared to Sonnet 4.5’s 18.5%. That’s not incremental improvement—that’s a qualitative leap.
In practical terms:
- You can actually feed in multiple related documents and trust the analysis
- Long research sessions don’t degrade as quickly
- Complex debugging across large codebases becomes genuinely useful
The context compaction feature (beta) is the unsung hero here. When conversations get too long, the model automatically summarizes older context on the server side. No manual prompt management, no context window gymnastics—it just works.
Writing and Creative Work: A Mixed Bag
Here’s where I need to be honest: several independent reviewers ran blind tests comparing Opus 4.6 and 4.5 prose, and many preferred 4.5’s output.
In my testing, Opus 4.6 tends toward more structured, formal writing. It loves constructions like “X not Y” and “Rather than A, consider B.” Technically correct, often helpful for documentation—but it has a distinct “AI smell” that experienced readers will notice.
Where it excels:
- Technical documentation that needs to be comprehensive and accurate
- Research synthesis across multiple sources
- Editorial consistency when applying specific style rules
Where Opus 4.5 might still be better:
- Creative fiction with natural dialogue
- Marketing copy that needs personality
- Blog posts where conversational tone matters more than precision
One reviewer noted it best: “The drafting experience is more fluid, but in a blind test, the team preferred 4.5’s prose.” I agree with this assessment.
Agentic Workflows: The Future Is Here (Kind Of)
Agent teams—where multiple Claude instances work in parallel—is still in research preview, and it shows. When it works, it’s genuinely impressive. I set up a team where one agent handled frontend changes, another tackled backend logic, and a third managed tests.
The coordination wasn’t perfect, but it was functional. The lead agent successfully delegated work and integrated results without my intervention about 70% of the time. The other 30%? I had to step in and manually reconcile conflicts.
Critical consideration: Each agent has its own context window, which means token costs multiply fast. A single complex session can burn through your usage cap surprisingly quickly. Anthropic recommends agent teams only for genuinely complex scenarios where parallel work makes sense.
The Benchmarks That Actually Matter
I’m generally skeptical of benchmarks—they measure what’s easy to measure, not always what’s important. But some of Opus 4.6’s results do translate to real-world capability:
GDPval-AA (knowledge work tasks): Opus 4.6 scored 1606 Elo, outperforming GPT-5.2 by 144 points and Opus 4.5 by 190 points. This benchmark tests economically valuable work in finance, legal, and technical domains. In my testing, this manifested as better multi-source analysis and more reliable financial modeling.
Humanity’s Last Exam: Leads all frontier models on this complex multidisciplinary reasoning test. What this means practically: the model can actually handle questions that require integrating concepts from multiple domains, not just pattern matching.
ARC-AGI 2: Nearly doubled from 37.6% to 68.8%. This tests novel problem-solving—the ability to tackle tasks the model hasn’t seen before. This is the benchmark that most impressed me because it correlates with handling unexpected real-world scenarios.
CyberGym: In testing by Norway’s sovereign wealth fund (NBIM), Opus 4.6 produced the best results in 38 out of 40 cybersecurity investigations in blind comparisons. If you’re in security, this model is worth serious evaluation.
Pricing: Where Things Get Complicated
Base API pricing is straightforward and unchanged from Opus 4.5:
- Input tokens: $5 per million tokens
- Output tokens: $25 per million tokens
Sounds simple, right? Here’s where it gets messy.
The Hidden Cost: Adaptive Thinking
Opus 4.6 generates invisible “thinking” tokens as it plans and verifies its work. A query that consumed 1,000 output tokens on Opus 4.5 might consume 2,500 tokens on Opus 4.6 because of this extended reasoning.
The model defaults to “high” effort, which means it thinks deeply even on tasks that don’t strictly require it. Users report that complex sessions on claude.ai can exhaust the five-hour usage limit in under 40 minutes.
Solution: Use the /effort parameter to dial down reasoning intensity. Setting it to “medium” for straightforward tasks can reduce costs substantially while maintaining good performance.
Premium Pricing Tiers
Long context (>200K tokens): $10/$37.50 per million input/output tokens
- Only kicks in when you exceed 200,000 input tokens
- Worth it for analyzing entire codebases or multi-document research
- Costs jump significantly, so use strategically
Fast mode (research preview): $30/$150 per million tokens (6x standard pricing)
- Delivers 2.5x faster output speeds
- Makes sense for real-time debugging or interactive work where latency kills productivity
- Absolutely not worth it for batch processing or background tasks
US-only inference: 1.1x multiplier on all token categories
- Required for certain compliance scenarios
- Marginal cost increase for data residency guarantees
Batch API: 50% discount for asynchronous processing
- Combine with prompt caching for maximum savings
- Perfect for large-scale non-urgent work
What You’ll Actually Pay
For typical usage (software development, content analysis):
- Light users: $20-50/month on standard pricing
- Active developers: $100-300/month with adaptive thinking on high
- Enterprise workflows: $500-2000+/month depending on agent teams and long-context usage
The billing model rewards strategic use. Run simple tasks on Sonnet 4.5 or Haiku 4.5, reserve Opus 4.6 for complex work that actually needs that reasoning depth.
The Real Limitations Nobody Talks About
1. It Overthinks Simple Problems
This is the Achilles heel. The model’s default “high” effort setting means it’ll spend 15 seconds reasoning about whether to add a console.log statement. For rapid iteration, this gets old fast.
Mitigation: Set effort to “medium” or “low” for simple tasks. The quality difference is negligible, but the speed improvement is substantial.
2. Writing Quality Regression
Multiple independent reviews found that Opus 4.5 produced more natural prose. Opus 4.6 is more thorough and accurate, but it has that distinctive “this was written by AI” feel that experienced readers notice immediately.
If writing quality matters more than technical accuracy, stick with Opus 4.5 for now.
3. Cost Unpredictability
The invisible thinking tokens make it hard to predict costs accurately. What looked like a 1,000-token response might actually consume 3,000 tokens. This isn’t a dealbreaker, but it requires monitoring your usage more carefully.
4. Agent Teams Are Still Beta
The parallel agent feature is promising but not production-ready. You’ll hit coordination failures, need manual intervention, and burn tokens faster than expected. Use it for experimentation, not critical workflows.
5. Speed vs. Capability Trade-Off
Opus 4.6 is measurably slower than 4.5 for simple tasks. If you’re doing basic question-answering or straightforward code generation, the extra capability doesn’t justify the latency hit.
Who Should Actually Use Claude Opus 4.6?
After 48 hours of real-world testing, here’s my honest assessment:
Perfect For:
- Senior developers working on complex refactoring – The planning and cross-file comprehension is genuinely useful
- Researchers analyzing multiple long documents – The 1M context window with reliable retrieval changes what’s possible
- Financial analysts building complex models – The GDPval-AA scores translate to real capability here
- Security professionals – The CyberGym results aren’t marketing fluff; this model excels at investigation work
- Legal work requiring document analysis – 90.2% on BigLaw Bench with 40% perfect scores is genuinely impressive
Not Worth It For:
- Simple coding tasks – You’re paying premium prices for capability you don’t need
- Creative writing projects – Opus 4.5 produces more natural prose at lower cost
- Cost-sensitive use cases – The thinking token overhead adds up quickly
- Time-sensitive rapid iteration – The slower response times kill productivity
- Basic chat and Q&A – Sonnet 4.5 handles this at a fraction of the cost
Maybe Worth It For:
- Medium-complexity coding – Depends on whether the better code review justifies the cost
- Technical documentation – The accuracy is excellent, but watch for AI-isms in the writing
- Multi-agent workflows – If you’re comfortable with beta software and high token costs
My Recommendations After Real-World Testing
If you’re already on Opus 4.5: Switch to 4.6 for coding workflows and complex analysis. Keep 4.5 around for writing-heavy tasks until the prose regression gets addressed. Use the effort parameter aggressively to control costs.
If you’re choosing between GPT-5.2 and Opus 4.6: Opus 4.6 leads on knowledge work benchmarks (GDPval-AA) and agentic coding (Terminal-Bench 2.0). GPT-5.2 is faster for simple tasks. Your workflow determines the winner—there’s no universal answer.
If you’re on a budget: Start with Sonnet 4.5. It handles 90% of tasks at a fraction of the cost. Reserve Opus 4.6 for the genuinely complex 10% where the capability difference matters.
If you’re evaluating for enterprise: The long-context performance and agent teams justify serious evaluation for knowledge work and codebase management. Start with a pilot project, monitor token usage carefully, and set realistic expectations around beta features.
The Bottom Line: Is Claude Opus 4.6 Worth It?
For the right use cases, absolutely. This is the first AI model I’d trust with genuinely autonomous long-running tasks without constant supervision. The 1M context window with reliable retrieval isn’t just a bigger number—it enables qualitatively different workflows.
But it’s not a universal upgrade. The slower response times, higher effective costs, and writing quality trade-offs mean you need to be strategic about when to deploy it.
My honest take after 48 hours: Opus 4.6 excels at exactly what it was designed for—complex, long-horizon tasks requiring sustained reasoning and reliable context management. For everything else, cheaper alternatives perform just as well.
The model represents a clear step toward AI that can genuinely complete professional-grade work autonomously. We’re not quite there yet—agent teams still need babysitting, costs are unpredictable, and simple tasks get overthought—but the trajectory is clear.
If your work involves complex analysis, large codebases, or multi-step reasoning where accuracy matters more than speed, Opus 4.6 is worth serious evaluation. For rapid iteration on simple tasks or creative writing, stick with what you have.
The future of agentic AI is promising. Claude Opus 4.6 gives us a preview of what that future looks like—including both the capabilities and the rough edges that still need smoothing out.
Frequently Asked Questions
Q: Can I use Claude Opus 4.6 for free? A: Anthropic offers free testing credits for new API users. For ongoing use, you’ll need a paid API account or claude.ai subscription (Pro, Team, or Enterprise).
Q: How does the 1M context window compare to competitors? A: Most models offer 128K-200K token windows. The 1M window is currently unique to Opus-class models from Anthropic, though premium pricing applies above 200K tokens.
Q: Will agent teams replace human developers? A: No. Agent teams are excellent for parallelizing routine work, but they require human oversight for critical decisions and handling edge cases. Think “force multiplier” not “replacement.”
Q: Should I migrate from GPT-5.2 to Opus 4.6? A: It depends on your workload. Opus 4.6 leads on complex reasoning and agentic coding. GPT-5.2 offers faster inference on simpler tasks. Test both on your specific use cases before committing.
Q: How do I control the thinking token costs? A: Use the /effort parameter. Set it to “medium” or “low” for routine tasks. Only use “high” or “max” when you genuinely need deep reasoning. This can reduce costs by 40-60% for typical workflows.